APM vs. Application Performance Observability - What’s the Difference
Published on by Eric L. Barnes

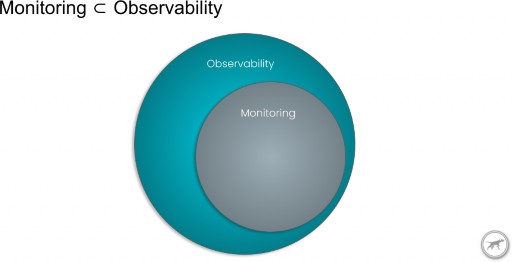
You’ve likely heard the term Observability lately. There’s a fundamental change taking place in the Monitoring space, and Observability is behind it. Observability itself is a broad topic, so in this post we’ll talk about what it means to move from Application Performance Monitoring to Application Performance Observability .
APPLICATION PERFORMANCE MONITORING
If you’ve used a traditional APM service, you’ve likely installed a library into your application from that APM provider. This library, or agent, would then gather metrics and application traces while your application runs in production.
Traces and Metrics in APM
Traditional APM agents collect detailed traces about what happens under the hood to in order for your application to serve transactions to end users. But they are also heavily metrics based. They generate predefined, aggregate metrics about the performance of the application as a whole. Metrics like throughput, response time averages and percentiles, etc. A dead giveaway as to whether a service is geared towards Monitoring or Observability is the overwhelming presence of dashboards for metrics. That’s not to say dashboards have no place in an Observability tool, but they should not be the main feature. You shouldn’t be investing a significant amount of time setting up or maintaining dashboards.
Lack of Context
Because traditional APM services are still heavily metrics based, there is a huge amount of missing context in the data. Without the contextual information from every application trace, it’s impossible to ask important questions like “What changed? Why? Who is affected?”. The detailed traces collected from APM tools are selected based on a simple sampling strategy.
Long Tail Questions
Traditional Application Monitoring is proficient at addressing the performance issues that impact the majority of users. Big picture problems, like “Is the site up?”, or “Is the 95% response time within our SLA?” can be answered with Monitoring. The long tail questions can only be addressed with an Observability solution . “Show me all users that had response times over our SLA threshold at any time this month”, “The 95% response time increased within the last hour. Display all services that are involved in servicing these requests, and which users are impacted”, “User X is having long load times on endpoint Y. Show me all traces from user X on endpoint Y”. Observability enables the ability to ask these questions and much more about your applications.
Duplicated Efforts
APM providers wrote agents to dynamically inject code into application frameworks and libraries, like Rails, Redis, and MongoDB. This enabled the collection of telemetry data from running applications. Instrumentation was a difficult, tedious, and delicate process, and each APM provider had to write their own. This resulted in wasted effort in instrumenting frameworks and libraries.
Settle for a Subpar Single Pane
Particular languages supported, robustness of APIs, consistency of naming conventions, and a multitude of factors prevents the sharing or integration of Monitoring data. Ops, Developers, SRE, DevOps all have their favorite tools. Each respectively chose the best tool to meet their needs in the past, which led to tool and service sprawl. Going for that single pane of glass? Get ready for some major subpar trade-offs for at least a few of these teams in order to get everyone on the same service.
APPLICATION PERFORMANCE OBSERVABILITY
Context Connects All
Instead of the APM agent determining which aggregated metrics to collect ahead of time, collect every application trace. When needed, derive metrics from the traces on demand. Slice and dice on facets of contextual information contained in the traces on demand. Contextual data is the cornerstone to be able to ask crucial Observability questions and answer those Long Tail issues.
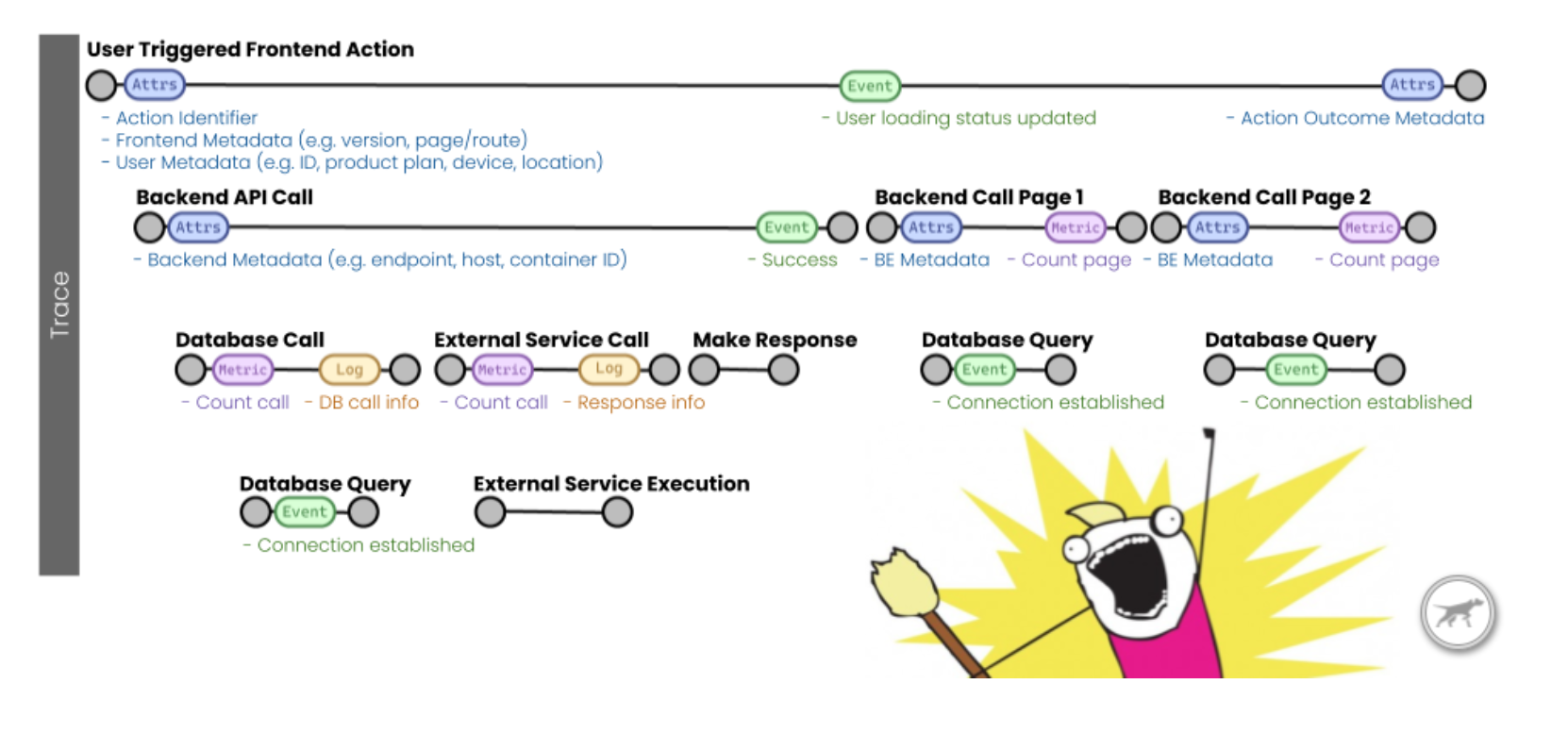
Implementing standards, cross language, and cross platform is a massive undertaking. You must be able to issue a query to answer your Observability questions across all languages you run in production. And also know that the context is applied and located in the same place across your applications. A framework that defines these standards is a must for Observability.
Shaping the Obs Landscape
The standardized specification point has a huge influence here. Here’s a list of some of the external interface port types I remember having to use on computers over the years: Parallel, RS232, DB9, VGA, S-Video, DVI, DisplayPort, HDMI, MIDI, RCA, Component, Toslink, RJ11, RJ45, PCMCIA, SCSI, eSATA, AT, PS/2, Firewire. Yes, I do have a box full of cables to connect to any one of these, sans PCMCIA…
Did you notice what was missing in the list? Right, USB! Of course I have a million USB cables. Because every single thing that connects to my computer is now USB . Sure, different form factors, but the protocol is magically backwards compatible. If you can make it fit, or flip it upside down once or twice – or more – it just works! This is the kind of standard every peripheral device manufacturer got behind because it’s so well designed. This is a huge part of what’s shaping the Observability landscape and finally getting an overwhelming amount of providers and developers to back a single specification: OpenTelemetry .
Correlations
I’ll stay on theme here: standardization . With a universal and consistent understanding of what data represents, we can make deep correlations across applications, languages, and infrastructure stack. This rich context enables machine assistance in performance and operational debugging, not just within a single application.
Development Culture Shifts
Observability is more than just a tool. It can’t give you omniscient powers like in the movie “ Limitless .” Observability needs to be intentionally added to your code and stack. Developers must remember to add it while writing and reviewing code. They should ask questions like “Does this need to be measured?” or “How do I know this will perform as expected?” Proprietary APM solutions can be a great start, but you need to make observability a regular thought in your code. Don’t forget to attach contextual information for future review of performance traces.
FACTORS ENABLING APPLICATION PERFORMANCE OBSERVABILITY
Cost-Effective Computing and Storage Solutions for High-Cardinality Big Data
Observability is all about high cardinality and big data sets. Cloud compute and storage cost has hit an inflection point. We can now leverage these cloud services for on-demand processing to answer the questions Observability demands and provide them at a reasonable cost to our users.
Open Source Observability APIs/SDKs.
We’re finally seeing the convergence of multiple competing standards being coalesced into one, with a huge amount of community and industry support: OpenTelemetry ! The OpenTelemetry Specification defines the cross-language data specifications including the API, SDKs, and transport protocols. These are forming the new ‘lingua franca’ for Observability , allowing the full stack to speak the same language, gather data in the same format, and ultimately transport that data for processing. To make Observability truly ubiquitous, we require this crucial puzzle piece.

APPLICATION PERFORMANCE OBSERVABILITY
OpenTelemetry evens the field for collecting, processing, and transmitting telemetry data with rich context. It does so uniformly across popular languages and system stacks. This focuses the value prop of Observability providers like TelemetryHub onto what insights and value you can derive from this newly unified data . This is an inflection point in the monitoring and observability landscape, and the next few years promise to be extremely interesting.

At TelemetryHub , we’re building a new Observability platform based on OpenTelemetry. Our focus is on providing actionable insights that quickly surface issues, giving your developers the confidence to address performance issues in increasingly complex applications and infrastructure.