Here are the 10 best practices that you can follow for your APM setups:
Best Practice #1: Don’t Build Your Own APM Solution(s)
Every organization comes across this build vs. buy dilemma at some point or another – do you develop your own set of tools for your project(s), or do you go ahead and buy an existing, working solution? However, when it comes to APM tools, you are much better off not trying to handcraft one for your organization.
The primary purpose of APM tools is to take care of unexpected issues in your application. If you build a custom APM solution for your application, you expose yourself to more issues across two platforms – your project and the APM tool itself. Therefore, it is much better to rely on more foolproof, trustworthy, specialized APM tools in the market. Besides, many of these tools are quite affordable and are therefore a much more viable option.
There are already many challenges and difficulties associated with running and maintaining applications at scale. By using an existing reliable APM solution, you now have one less thing to worry about. Do what you do best, and let outsourced expertise take care of the rest.
Best Practice #2: Ensure You Have the Right Tool(s) for the Job
After discussing the advantages of going for a third-party APM suite instead of building one for your own, it’s time to focus on things you need to keep in mind when opting for a tool that works best for your application. Before choosing an APM tool, it is important to research your application requirements, service-level agreements (SLAs), and customers; then, see what feature set suits your setup best. There are a bunch of factors that you need to consider for this. These include the APM’s feature set, pricing model, flexibility, programming language support, data granularity, user interface, integration with other tools and services, technical support, ease of use, and many more.
Some APM tools might focus on monitoring some minimal but essential operations, while others may go above and beyond in providing a comprehensive list of features.
Therefore, having a good understanding of what you need from these tools and at what cost will help you make an informed decision.
Are you confused about the plethora of APM tools in the market? We have got you covered with an elaborate analysis of the top 9 APM tools in the “A Comparison of the Top 9 Application Performance Monitoring Tools” post that you can check out on our blog.
Best Practice #3: Set Up a Customized Dashboard with the Most Useful Information
When using APM tools for monitoring large-scale applications, you are likely to have many metrics, graphs, and other data visualizations thrown at you, which can sometimes make it difficult to focus on the aspects of performance that really matter. To this end, several APM tools provide an option to customize the appearance of your dashboard page.
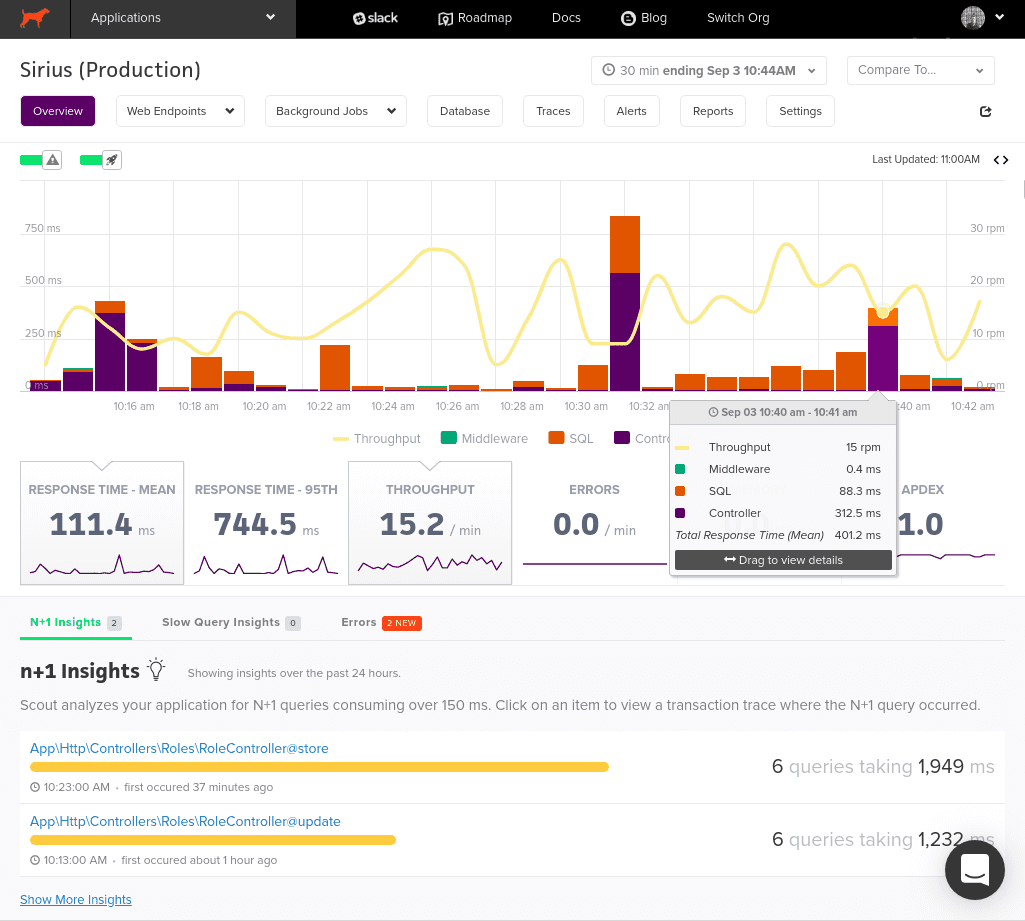
Your dashboard is the first page that opens up when you log in to your APM service. This page is supposed to present you with a broad idea of how your application is faring overall. Therefore, when setting up your APM tool, you should spend some time understanding what metrics provide the most relevant and vital information about the functioning of your application. Once that is done, the next obvious step is to ensure that these receive considerable attention in the dashboard you set up.
Best Practice #4: Prioritize Critical Transactions
In most cases, you’ll find that some transactions in your application are more critical than others. For example, you would be more concerned about the user’s home page’s response times than those of a rarely used static Terms and Conditions page.
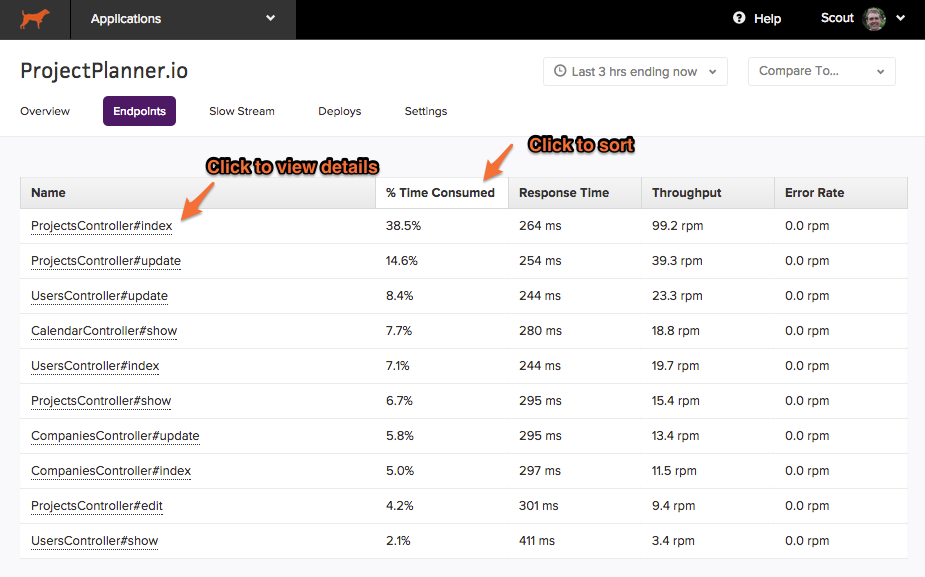
These last two practices should declutter your setup quite a bit – letting the more important metrics and functions shine through and convey more actionable information about what is working well and what needs to be optimized.
Best Practice #5: Configure Custom Alert Policies and Notifications
When issues arise, and performance drops, individuals in your team need to be updated about the impact before the end-user catches wind of anything. After all, what is the point of a real-time alerting system if these alerts aren’t properly set up, they don’t reach you where you’d like, or you are unable to act on them?
As we have discussed before, each application and organization differs in different aspects. Therefore, based on your requirements, you might want to set up your own set of alerting conditions – because what may be worth receiving an alert for in your application will differ from what it would be for in another application. All APM tools allow you to create alerting policies by specifying thresholds on different metrics like response times, error rates, ApDex score, etc.

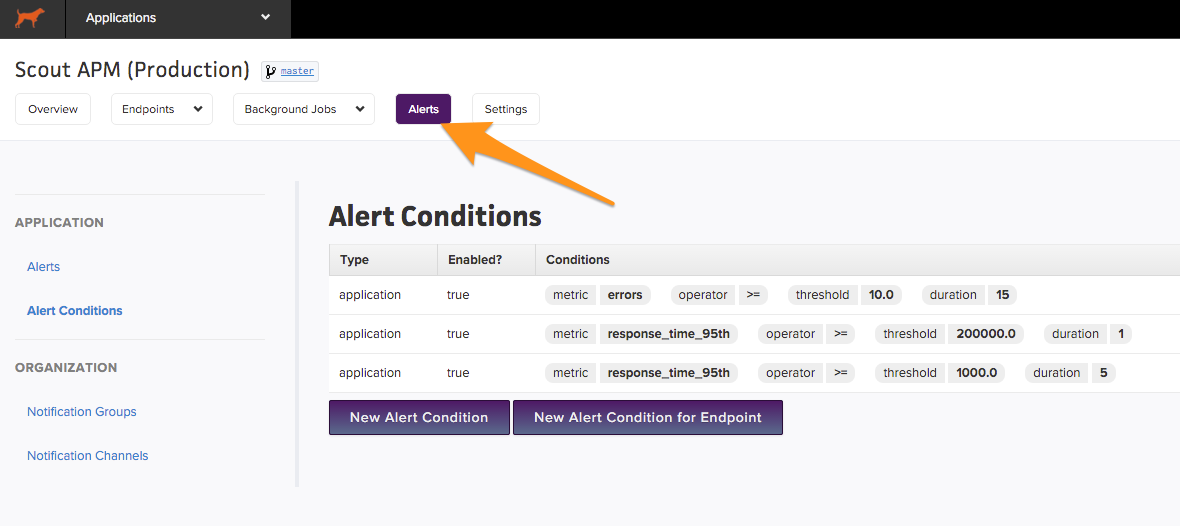
Apart from email alerts, tools like ScoutAPM also allow you to integrate these updates with a messaging platform like Slack, making it easier for teams to stay updated and collaborate easily.

Also, you might not want to just stop at setting up these alert policies. Internal systems and processes should define the delegation of these issues and other practices that can ensure the corresponding issues are resolved efficiently.
Best Practice #6: Factor in the End User Experience
As we previously discussed, it is the end user’s experience that matters most. And end-users expect faster applications and smoother experiences. Therefore, it is important to be on the lookout for patterns related to the ApDex score of your application. For example, you might observe sudden drops in the score after particular deployments or repeated peaks in response times that might rapidly lower the ApDex score, indicating a likely infrastructure limitation.
Your application’s ApDex scores are visible throughout the ScoutAPM platform and can be easily toggled on or off at any time.
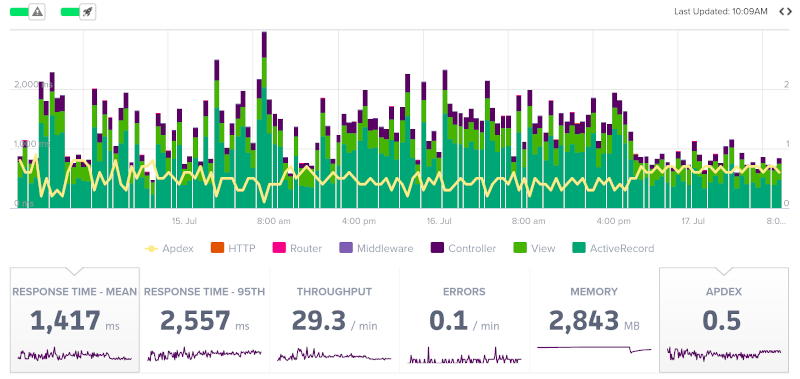
Therefore, when other performance metrics are alone unable to present a clear narrative of your application’s performance, it can be a good practice to start with the ApDex score and take things from there.
Best Practice #7: Keep Up with the Manual Checks (every once in a while)
The software industry is an extremely fast-paced one. Things quickly change – usage patterns evolve, requirements change, expectations change. Alerts and policies, once set up, might not be relevant throughout. Given how precariously poised many of our applications are and the various number of things that can go wrong, it’s essential to have occasional manual checks to ensure that things are in order. This can include periodic checkups for inconsistencies and inaccuracies and providing the metrics and policies initially set up are scaling with the growth of your application. After all, no news is not good news.
Best Practice #8: Be Intelligent in Interpreting Metrics – Don’t Oversimplify
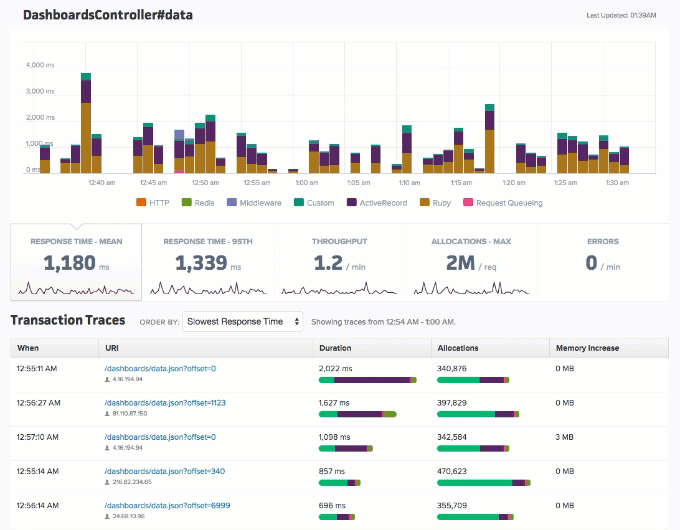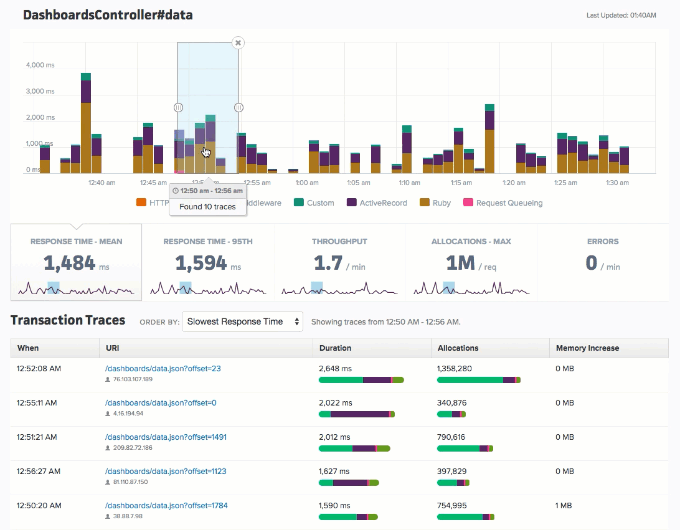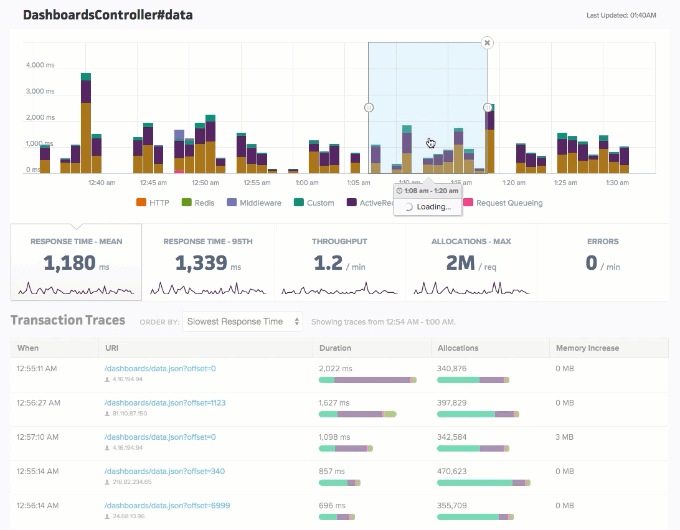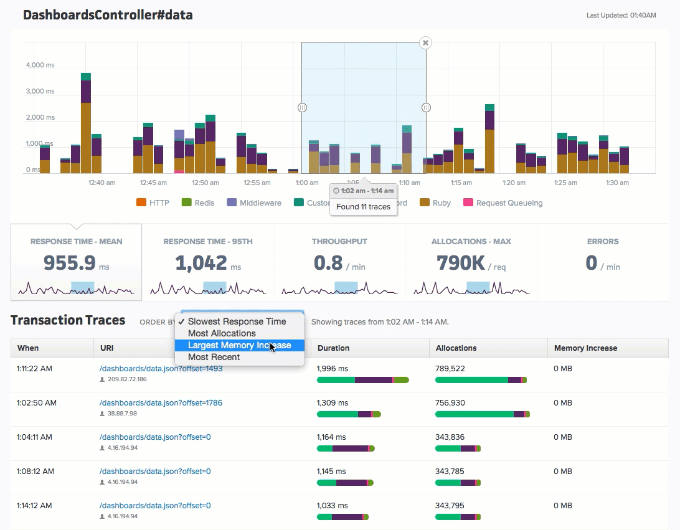
Most APM tools in summarizing performance metrics present an average (or mean) of all metric values.

Even though an average is perhaps the most plausible (and easily understood) indicator of performance on a broader scale, organizations might occasionally want to dig deeper into these metrics. Let’s see why this is through an example.
Consider an end-point that has a mean response time of 1 ms. This gives an impression of most (if not all) users experiencing a 1 ms response time. However, the average response time can also find a way to be 1 ms even when 20 percent (or any arbitrary percentage less than 50) of your audience experiences a 2x (or 3x or 4x) response time. This is what we like to refer to as the average fallacy. In this case, individuals can overlook the response times’ distribution and be content with the lower overall average. However, by carefully analyzing the metrics, as shown below, the organization can focus on ways to optimize the response times for the rest.
Best Practice #9: Train Personnel for Working with APM Tools
APM tools do need some playing around to get acquainted with the many features they offer. Usually, getting the most value out of them requires some hands-on experience and understanding of the best practices to follow. Therefore, it would be a good practice to train individuals in your team about the operations of these tools.
Organizations can decide for themselves whether they need a dedicated group that overlooks APM operations or wants everybody to pitch in and take APM insights for their own work. For example, developers can benefit a lot from some minimal training with an APM platform. This can help them understand the business importance of application performance and code and build software accordingly. On the other hand, if a dedicated group is assigned to take care of everything APM, it makes things much more systematic as there is a clear understanding of responsibilities. This minimizes the chances of things falling through the cracks.
Most APM tools offer great documentation that makes getting started with these tools super easy!
Best Practice #10: Don’t Hesitate to Seek Help
All top APM tools out there provide excellent technical support for their customers and provide support quickly. However, in working with the most highly intuitive platforms, teams might not feel the need to consult or seek external help. As a result, operators might miss out on several valuable features, tips, and tricks.
It’s valuable to get some guidance and insight from your APM tool’s support team. They have much more experience dealing with everyday issues that organizations might face with their APM tool and provide constructive feedback. Therefore, this can help improve how you utilize the APM tool and make the most out of it.
Summary and Important Takeaways
It is important to note that if you are just starting with web development and working on smaller, personal projects, understanding the importance of APM tools might not come easily or seem super relevant to you. However, these tools become exponentially more valuable as your application(s) scale up and cater to hundreds or thousands of users.
If you are interested in:
- using performance insights to improve your application and business,
- getting centralized observability and continuous insight into your application’s availability and performance,
- saving time, energy, and resources in laborious, error-prone manual inspection and monitoring,
- proactive alerting, real-time insight, and always-on support, and
- spending less time debugging issues and more time building new features;
Then check out ScoutAPM by signing up for a free trial - you can thank us later.